
Qu'est-ce que Node.js ?
#1
A quoi sert Node.js ?

Node.js vous donne la possibilité de programmer en JavaScript sans avoir besoin d'un navigateur. Node.js vous l'installez sur votre machine de développement, un PC ou sur un serveur et vous pouvez faire du JavaScript 😃. Eh oui, jusqu'à ce que Node.js existe, pour programmer en JavaScript, on se servait d'un navigateur.
Ce qu'il faut comprendre, c'est que bien que ce soit du JavaScript des deux côtés (navigateur ou serveur), eh bien, avec ce JavaScript, vous ne ferez pas la même chose selon que vous êtes côté serveur ou côté navigateur.
Avec un navigateur, la plupart du temps, on va chercher des données sur un serveur et on se sert de ces données pour modifier le document qui est affiché dans la fenêtre du navigateur.
Avec le navigateur, on n'a pas accès à toutes les ressources du système d'exploitation. En particulier, on ne peut pas accéder au système de fichier et heureusement, car il y aurait des problèmes de sécurité.
Avec Node.js, il n'y a plus de document. Mais par contre, avec Node.js, vous avez la possibilité d'utiliser les services du système d'exploitation.
Par exemple, vous pouvez ouvrir un fichier et écrire des données dedans.
Mais vous pouvez aller beaucoup plus loin et écrire un serveur http ou une application complète qui répondra aux requêtes du navigateur. Dans ce cas, on dit qu'on programme en JavaScript côté serveur. Et vous aurez besoin d'outils complémentaires à Node.js.
#2
Des entrées/sorties Asynchrones !!
Vous savez sans doute que JavaScript gère des entrées/sorties asynchrones. C'est ce qu'il fait sur un navigateur. Sur un système d'exploitation, Node.js va devoir lui aussi gérer des entrées/sorties asynchrones. Ca c'est capital, car ça va changer pas mal de choses.
(* Node.js conserve la possibilité de faire des I/O synchrones, mais ce n'est pas ce qui nous intéresse)
#3
Qui a construit Node.js ?

#4
Comment est construit Node.js ?
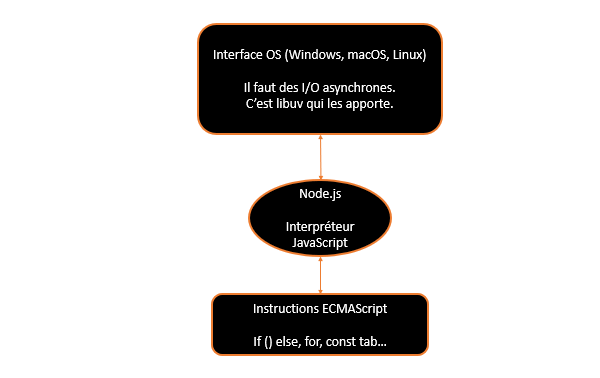
Ryan Dahl pour construire Node.js va récupérer plusieurs choses.
La première chose qu'il récupère vient du projet Chromium. C'est le fameux moteur V8 . C'est un projet open source de navigateur qui a été utilisé pour faire Chrome (* qui lui n'est pas open source).
Attention, il faut comprendre ce qui a été fait pour passer d'un JavaScript prévu pour un navigateur à Node.js qui est un JavaScript qui doit tourner sur un système d'exploitation.
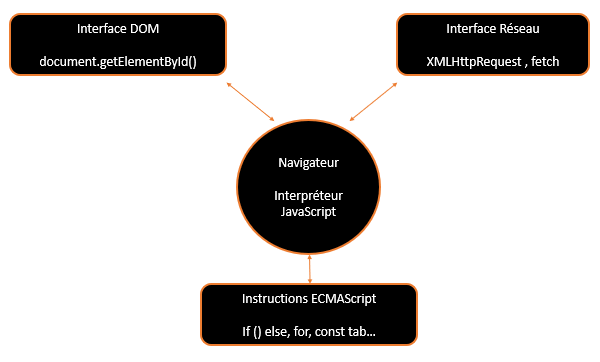
Pour ça, on va examiner grosso modo ce qu'il y a dans l'interpréteur JavaScript d'un navigateur et voir ce qui est récupérable. Dans un navigateur, l'interpréteur va rencontrer 3 catégories d'instructions :
-
Il y a les instructions qui appartiennent à l'interface avec le document. Ce sont les instructions du style
document.getElementById(). Il y adocument.en préfixe. Ca évidemment ça ne servira à rien. -
Ensuite, il y a les instructions qui permettent de communiquer avec les serveurs. Ca aussi, c'est une interface. Ca ce sont des instructions du style
XMLHttpRequestoufetch. Ca, ça fait des requêtes http, mais côté serveur, il va falloir répondre à des requêtes http. Donc ça, ce n'est pas récupérable. -
Il reste les instructions ECMAScript, c'est-à-dire le JavaScript pur, à savoir les structures conditionnelles, les boucles, les fonctions, les classes, et ça, c'est récupérable, et il faut bien voir que Ryan Dahl ne récupère que ça.
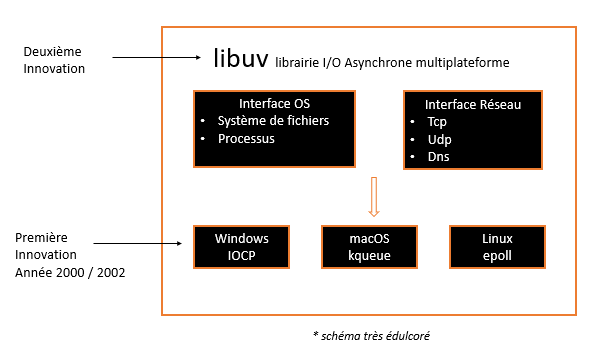
Ryan Dahl part de là. Il lui reste un défi de taille, c'est de faire une interface asynchrone avec l'OS qui soit multiplateforme, car Node.js doit tourner sur Windows, Linux et macOS au minimum. (* Aujourd'hui Node.js tourne sur plus d'OS que ça). Pour faire ça, il récupère libuv.
libuv c'est une librairie open source d'entrées/sorties asynchrones multiplateforme.
Cette librairie est développée pour Node.js et elle récupère elle-même des innovations qui date des années 2000/2002. Ces innovations, ce sont des librairies d'entrées / sorties asynchrones pour chacun des systèmes d'exploitations.
Vous avez :
epoolpour Linux.kqueuepour macOS.Iocppour Windows.
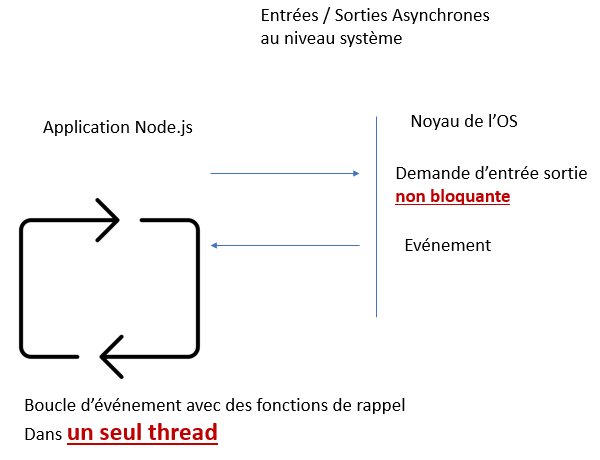
Lorsque l'on fait une entrée / sortie asynchrone au niveau système, ça se passe un peu comme sur un navigateur, on fait :
- Une demande d'entrée sortie, mais cette fois, on la fait au noyau de l'OS. La demande est non bloquante.
- Quand l'entrée/sortie est terminée, le noyau renvoie un événement.
- Les événements sont mis dans une boucle d'événements.
- Et ce sont les fonctions de rappel (les callbacks) qui récupèrent et traitent les informations.
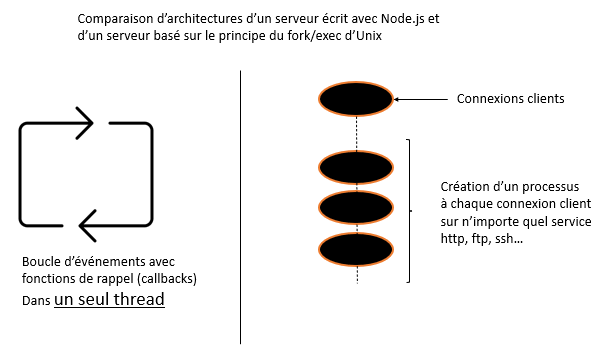
Bien sûr, tout ceci se fait dans un seul thread.
Attention, toutefois on est non bloquant sur les entrées / sorties, pas sur des calculs. Si vous entrez dans une boucle de calcul lourde, votre application sera par terre. A ce moment-là, il vaut mieux sous traiter le calcul à un serveur et récupérer le résultat ou alors créer d'autres threads.
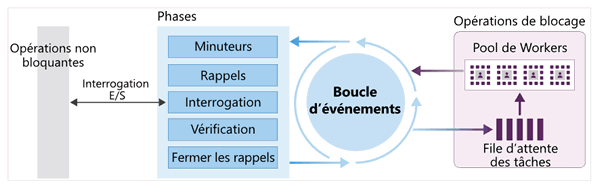
Visitez sur site de la documentation de Microsoft la rubrique intro-to-nodejs, vous y trouverez le schéma ci-dessous avec des explications complémentaires.
#5
Api de Node.js et npm
En septembre 2022, on travaille avec la version 16.17.0 LTS.
Vous avez ici, toutes les Apis asynchrones, par exemple, celle avec le système de fichier, celle avec http , celle avec les services DNS , celle avec laquelle vous pouvez créer d'autres threads. Avec ça vous développez n'importe quelle application côté serveur.
Celle avec le système de fichier, je la présente dans un tuto dédié à la découverte de l'Api de Node.js.
Mais que se passe-t-il si vous voulez faire par exemple un simple fetch pour aller chercher une ressource sur le réseau. Si vous cherchez dans la doc de l'api, vous ne trouverez pas l'équivalent d'un fetch. En tout cas pas pour cette version LTS, mais ça va venir dans les suivantes. C'est là qu'intervient un outil essentiel qui est livré avec Node.js et qui s'appelle npm. Alors, on peut retenir Node Package Manager pour la signification de l'acronyme npm. C'est pratique, mais le créateur de npm dit lui-même que ça ne vient pas de là.
npm c'est un gestionnaire de dépendances. Il est livré avec Node.js au moment de l'installation. Ca rappelle Composer pour ceux qui font du php. C'est un gestionnaire de dépendances qui va nous permettre de récupérer et d'installer des modules qui sont déjà écrits.
J'ai fait un tutoriel sur l'apport de npm dans l'environnement Node.js. Je vous y renvoie.
#6
Un serveur avec Node.js
Ci-dessous, vous avez le code d'un serveur http écrit en JavaScript sous Node.js. Ce code est extrait de la documentation.
Vous constatez qu'en quelques lignes, vous pouvez programmer un serveur http. La possibilité qui vous est offerte, c'est d'incorporer ce code à une application et de vous passer de serveur Unix style Apache ou Nginx.

Node.js va beaucoup plus loin que le simple fait de pouvoir programmer en JavaScript côté serveur. Ryan Dahl avec Node.js range dans les livres d'histoire de l'informatique le modèle client/serveur traditionnel qui date des années 80 et qui tourne sur tous les serveurs du monde. 🤩
Ce modèle est basé sur le couple fork/exec Unix. Il est utilisé pour tous les services disponibles sur un serveur Unix, à savoir http, ftp, ssh...
C'est un modèle qui consiste à forker (* créer un nouveau processus) à chaque connexion d'un client de manière à prendre en charge ce client. C'est une façon de procéder qui est très stable et très sécure, mais qui est coûteuse en ressources machine et temps. Node.js est beaucoup plus rapide.