


API Fetch

#1
Qu'est-ce que fetch ? Pourquoi l'utiliser ?

fetch c'est une fonction JavaScript native qui permet de faire des requêtes Ajax. Les requêtes Ajax, ce sont des requêtes HTTP, que l'on fait depuis le JavaScript du navigateur vers un serveur. C'est-à-dire que le navigateur va chercher des informations sur un serveur, par exemple pour rafraîchir la page web qu'il est en train d'afficher.
Avant que fetch existe, on utilisait pour faire nos requêtes Ajax, une interface qui s'appelle XMLHttpRequest. Alors pourquoi utiliser fetch ? Eh bien, la raison essentielle est que fetch travaille avec des promesses 😎. Autrement dit, un appel à fetch retourne un objet JavaScript de constructeur Promise.
J'ai déjà fait un tuto sur les promesses et également un tuto sur XMLHttpRequest.
Précisions :
- fetch ce n'est pas uniquement une fonction, on peut parler d'Api, c'est-à-dire ici, d'interface avec le réseau.
Les différents objets qui composent l'Api fetch 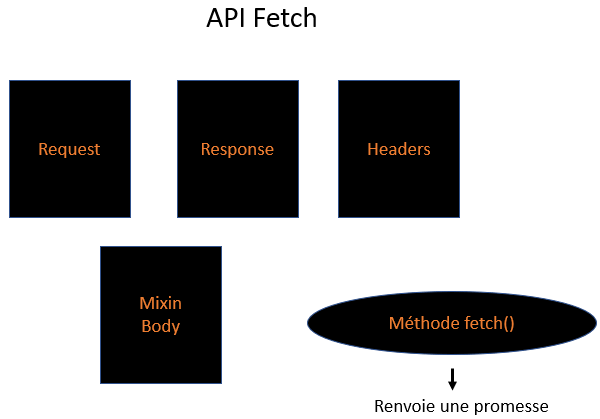
- Avec une requête ajax, on ne se contente pas d'aller chercher des données, mais on peut aussi en envoyer. Avec un
GET, on va chercher des données et avec unPOST, on envoie des données. On a aussi d'autres possibilités. On peut mettre à jour des données avec unPUTou unPATCH. On peut en supprimer avec unDELETE. On peut donc utiliser différents verbes HTTP. - Enfin, les promesses ne sont pas le seul et unique avantage de fetch.
#2
Premier fetch. Comment ça marche !
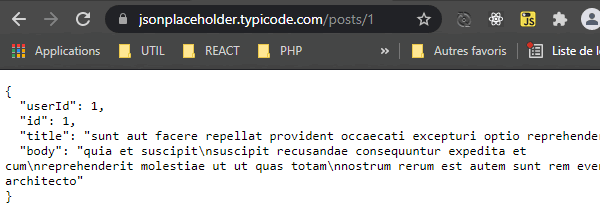
Tout d'abord, on va aller chercher des données au format JSON sur le site jsonplaceholder.typicode.com. Si on fait un tour sur le Guide, on voit que l'on peut avoir des données à cette Url https://jsonplaceholder.typicode.com/posts/1. Cliquez sur le lien, pour visualiser ces données dans un navigateur.
Maintenant, on va voir comment aller chercher ces données avec un fetch dans un code JavaScript. Pour ça, on va passer cette Url en argument de fetch, en tant que chaîne de caractères. Ensuite, puisque fetch nous renvoie un objet de constructeur Promise eh bien, on va faire un then et dans ce then, on va déclarer un callback. Ce callback reçoit en premier argument la réponse fournie par fetch. Ca on le sait, si on a étudié les promesses. Ca correspond au cas de l'appel du resolve. Alors, si vous avez fait les promesses, vous comprenez ce que je dis, sinon vous ne comprenez rien 😕. Donc, faites-les, c'est indispensable.
Avec le bout de code ci-dessous, on va voir justement comment fetch nous fournit la réponse. On va juste console logger cette réponse.

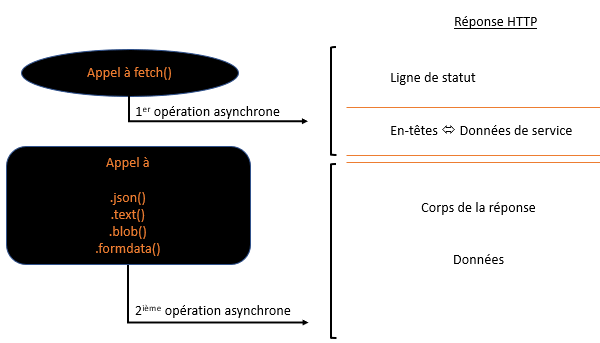
Donc ci-dessus, on visualise ce qu'il y a dans la réponse fournie par fetch :
- Un booléen
okqui nous indique si la réponse est correcte ou pas. Ok esttruepour des valeurs de retour de 200 à 299 inclus. - Une valeur de
status. Donc ici, on retrouve le fameux code de retour d'une requête réussie qui vaut200. - Un objet
headers. Si vous regardez cet objet, vous allez voir que vous avez accès à vos en-têtes avec de simples méthodes. Par exemple, la méthodeget()vous permet de lire la valeur d'une en-tête. La méthodehas()vous permet de savoir si une en-tête est présente dans la réponse HTTP. Tout ça, c'est synchrone. Donc à ce stade, au niveau HTTP, la ligne de statut et les en-têtes sont là. - Par contre, si vous cherchez vos données, eh bien, vous ne les trouvez pas. Vous allez trouver un prototype et dans ce prototype, vous avez de quoi accéder à vos données. Des données qui se trouvent à priori dans le corps de la réponse HTTP. Pour accéder à ces données dans notre exemple, on va utiliser la méthode
json(). Si on examine ça dans la doc, on voit que c'est une opération asynchrone qui renvoie une promesse. Ca veut bien dire qu'à priori, on n'est pas sûr que nos données soient là !! Sinon, on ne ferait pas de l'asynchrone. - D'ailleurs dans la doc, il n'y a que des opérations asynchrones pour aller chercher nos données. Par exemple, on a
blob().bloben autre ça permet de récupérer une image. On a aussitext(), pour des données textuelles. On a aussiformdata()qui retourne une promesse qui est résolue par un objet de constructeurformdata.
On se rend compte que pour aller chercher une ressource avec fetch, il faut faire deux opérations asynchrones. C'est ce qui explique que l'on voit presque toujours deux then qui accompagne chaque fetch. En réalité, la première opération asynchrone est faite par l'appel à fetch. Cet appel nous retourne un accès à la ligne de statut et aux en-têtes de la réponse. Ensuite, la deuxième opération asynchrone, c'est nous qui devons la faire. Et c'est celle-là qui nous permet d'accéder aux données. A la limite, vous pouvez, après l'appel à fetch, consulter vos en-têtes. Par exemple, le content-type avec le charset. Et en fonction de cela, vous choisissez la bonne opération asynchrone pour aller chercher vos données après avoir pris connaissance de leur format. Il y a un exemple dans la doc.
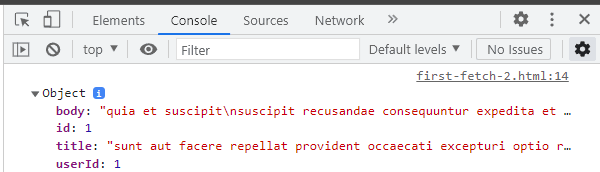
Donc ci-dessous, je transforme mon code de manière à coder moi-même l'opération asynchrone qui va me permettre, non seulement d'aller chercher mes données, mais en plus de les parser. C'est-à-dire que l'appel à .json(), va faire, en plus, l'équivalent d'un JSON.parse(). Donc, je vais récupérer un objet JavaScript.
Attention, ci-dessous, il n'y a pas de catch au niveau du fetch. Je fais cette remarque, car en plus, je me rends compte qu'ici, je parse sans aucune précaution. Dans d'autres conditions, si je faisais un JSON.parse, il faudrait le mettre dans un bloc try catch.
#3
Traiter les erreurs.
Dans l'exemple ci-dessous, je me sers du booléen ok pour mettre en place un filtrage des erreurs HTTP. Les erreurs HTTP, par exemple l'erreur 404 Not Found ou la 500 Internal Server Error sont à différencier des erreurs réseau.
Les erreurs HTTP peuvent se produire sans qu'il n'y ait le moindre problème réseau ni la moindre instruction JavaScript qui plante.
Lorsqu'une erreur HTTP se produit, je me sers d'un appel à Promise.reject() pour récupérer une promesse rompue et la retourner depuis le then. C'est ce qui permet d'aller se brancher sur le catch.
Dans l'exemple ci-dessous, il n'y a pas d'erreur. Donc, nous allons constater la récupération normale de nos données.
Tester le code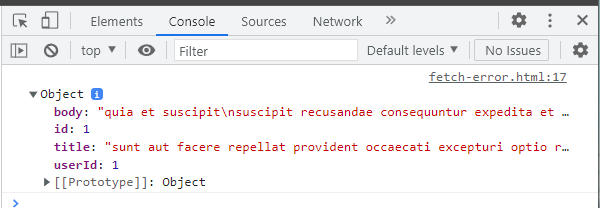
Maintenant, dans l'exemple ci-dessous, je vais volontairement provoquer une erreur en me trompant au niveau de l'Url. Et là, on va constater que l'on va au catch.
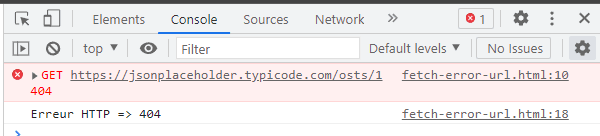
Attention, ci-dessus, on peut croire que dans notre code, il y a une exception qui n'a pas été traitée. En fait, c'est juste que Chrome visualise l'erreur HTTP comme une exception. C'est possible de cacher l'erreur HTTP comme je le fais ci-dessous en cliquant sur la roue crantée et en cliquant ensuite sur Hide Network.
Maintenant, on va regarder ce qui se passe si une exception se déclenche pour une raison quelconque dans une des méthodes then. En fait, JavaScript considère que le déclenchement d'une exception est équivalent à l'échec d'une promesse et le script ira au catch. Dans l'exemple ci-dessous, pour simuler, c'est moi-même qui déclenche l'exception avec un throw.

#4
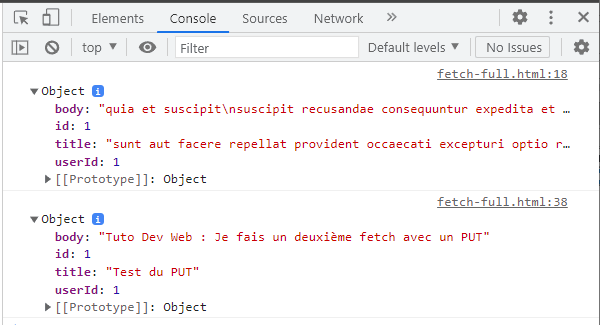
Deux fetch en cascade. Un GET suivi d'un PUT.
Maintenant, je vais mettre deux fetch en cascade. Dans le premier fetch, je fais un accès GET qui est l'accès par défaut. Dans le deuxième fetch, je vais faire un PUT pour modifier la donnée que je viens de recevoir.
Pour chaîner les opérations asynchrones, il faut avoir compris que chaque then doit retourner une promesse. Je rappelle qu'une promesse est un objet de constructeur Promise qui est doté des méthodes then et catch. Si la promesse est tenue, c'est le then suivant qui s'exécutera. Si la promesse est rompue, c'est le catch qui s'exécutera, le catch qui lui est commun à tous les then.

- Dans le deuxième
then, il faut que je fasse la copie de la donnée que me renvoie le premierfetch, car je veux la modifier. Je le fais dansnewDataen utilisant le spread operator. - Ensuite, je modifie les propriétés
titleetbodyde l'objetnewData. - Je prépare le deuxième argument du deuxième
fetchque j'ai appelémyInit. Je vais l'utiliser pour paramétrer monPUT. Il faut préciser que je fais unPUTdans le champmethod. - Dans le champ
body, je mets mes données, mais il faut que je les mette au format dans lequel je vais les envoyer. Donc là, je vais transformer mon objet JavaScriptnewDataen une chaîne de caractères au format JSON en utilisantJSON.stringify(). J'ai déjà fait un tuto sur JSON. - Dernière chose à faire. Il faut insérer l'en-tête
Content-typepour dire au serveur dans quel format sont les données que je lui envoie. Pour cela, j'utilise la propriétéheaderset je lui donne la valeur d'un objet qui va contenir des en-têtes. Ici, il n'y a que l'en-têteContent-type. - Ensuite, je fais le deuxième
fetch. Attention, il ne faut pas oublier lereturndevant lefetchde manière à retourner l'objetPromiseretourné par lefetch. - Ensuite, le traitement est identique au premier
fetch, il suffit de personnaliser le texte de l'erreur HTTP.
Le site jsonplaceholder.typicode.com nous renvoie la donnée modifiée, mais attention, ce n'est qu'une simulation. Ce n'est pas pour autant que vous avez un jeu de données privées. Si vous accédez à nouveau à la ressource, vous verrez qu'elle n'a pas été modifiée https://jsonplaceholder.typicode.com/posts/1. Tout ceci est expliqué dans le Guide.