
La POO pour quoi faire ?
#1
Comment fait-on sans la POO ?

Quand on développe un logiciel, quel que soit le langage, on a vite besoin de découper ce logiciel en modules 😃. Si on a un logiciel de 10 000 lignes de code, ce qui est petit, on ne peut pas mettre les 10 000 lignes dans le même fichier. Déjà, on n'arriverait pas à le manipuler en édition 🙃.
Lorsque l'on commence la conception d'un logiciel, ce que l'on fait, c'est une analyse fonctionnelle, c'est-à-dire qu'on identifie les grandes fonctions du logiciel. Si on n'a pas de classe 😒, eh bien, on va mettre ces fonctions dans des fichiers séparés. En fait, ces fichiers seront des modules. Des modules complètement rudimentaires, autrement dit de simples boîtes, des tiroirs.
Donc pour résumer, on fait une analyse fonctionnelle et on fait du rangement.
Par exemple, je reprends le TD numéro 5 que l'on vient de faire en programmation procédurale. On a fait un outil pour entraîner la mémoire.
C'est un outil qui vous pose une question. Vous devez essayer de trouver une réponse et la garder en tête. Puis, vous demandez l'affichage de la réponse pour vérifier.
On a identifié des fonctionnalités de gestion des données, on les a mises dans un fichier qu'on a appelé data.php. Ensuite, on a identifié des fonctionnalités d'affichage, on les a mises dans un fichier que l'on a appelé afficher.php. Ensuite, ces fichiers, on les a inclus dans un programme principal.
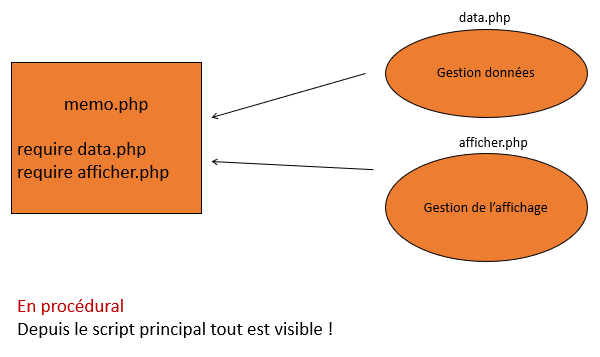
L'inconvénient, c'est que tout ce qui est inclus dans le programme principal est visible depuis le programme principal. Tout est mélangé et tout peut être modifié depuis le programme principal. En particulier, on peut casser ce qu'il y a dans data.php ou bien dans afficher.php.
#2
Le premier avantage de la POO c'est l'encapsulation
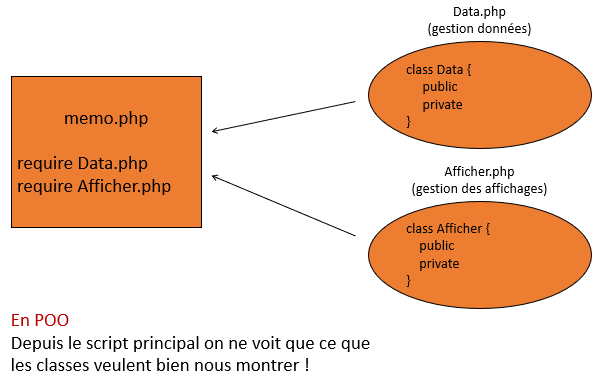
Avec la POO, l'analyse fonctionnelle ne va pas changer. Par contre, on va mettre les fonctionnalités dans des classes. Dans ces classes, on peut choisir les parties de codes qui seront visibles depuis l'extérieur de la classe et celles qui ne le seront pas. On va donc pouvoir encapsuler certaines informations et les protéger 😆.
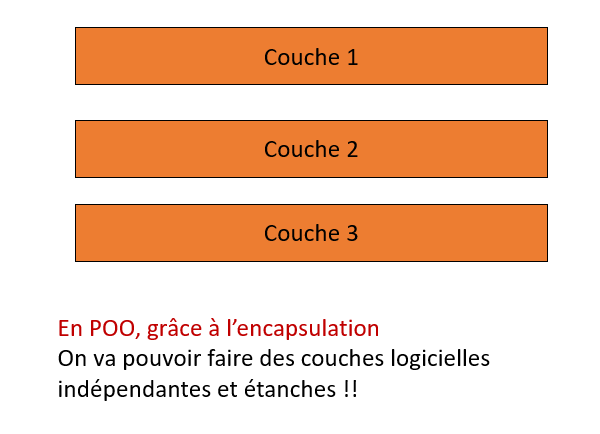
De cette manière, on va pouvoir faire une chose importante, on va pouvoir développer des couches logicielles indépendantes et surtout complètement étanches. Ci-dessous, la couche 1 ne peut pas venir casser la couche 2. Le langage ne le permet pas !
On peut aussi cacher la complexité de la couche 2 à la couche 1 qui se fiche pas mal de savoir comment est implémentée la couche 2 qu'elle utilise.
En plus, on verra lorsque l'on refera le TD 5 en utilisant la POO, qu'il sera possible d'initialiser les couches indépendamment les unes des autres. Il faut avoir en tête que dans beaucoup de logiciels, il y a une phase d'initialisation au moment du lancement. Un boot en quelque sorte. C'est le moment où l'on crée les ressources nécessaires à l'application (processus, bancs de mémoires partagées, sémaphores, sockets, connexion database etc). On verra, qu'avec la POO, il sera possible d'encapsuler des morceaux de cette phase d'initialisation et de créer les ressources au plus près de leur utilisation.
#3
Le deuxième avantage de la POO
En POO on a un mécanisme de création des objets à partir d'un modèle qui est leur classe.
Tout de suite un exemple, si je fais une boutique en ligne, je vais avoir besoin d'une structure de données qui va regrouper les caractéristiques des articles que je vends dans cette boutique en ligne. A savoir, le nom de l'article qui est une chaîne de caractères, la référence de l'article qui est aussi une chaîne, et le prix hors taxes qui lui est un flottant. Vous voyez que ce dont j'ai besoin, c'est ce que l'on appelle un type structuré. Ce type structuré est une structure de données (* c'est la même chose) et on va la mettre dans la classe. Et dans la classe, on va encore aller encore plus loin, car à ce type, on va ajouter toutes les opérations que l'on peut faire dessus. Par exemple, nous, on va mettre dans la classe une fonction qui permettra de calculer le prix TTC.
En PHP, ça nous donnera le code ci-dessous :
Il y a un avantage évident, que vous pouvez voir tout de suite, qui est qu' Article devient en quelque sorte un nouveau type. Un type qui s'ajoute aux types prédéfinis (* entier, flottant, string, tableau, enum). En fait, en POO, on ne parle pas de type structuré. On dit que, $article1 et $article2 sont des objets de la classe Article. Des objets que l'on peut créer en une seule ligne de code. Et on pourra, par exemple, passer en argument d'une fonction une variable de type Article. Cette variable étant un objet.
Il faut bien voir, ci-dessus, que dans $art il y aura une structure de données, avec des données dedans, et aussi toutes les fonctionnalités qui sont nécessaires pour manipuler ces données. C'est pas mal non ! 😀
#4
Le troisième avantage de la POO c'est l'héritage
Hé oui ! Vous voyez que l'héritage n'arrive qu'en troisième position (Pour moi en tout cas. Je l'assume.). Supposez maintenant que l'on mette des articles en promotion. On veut faire une remise et calculer le prix de l'article en promotion. On ne veut pas tout recommencer. Un article en promotion est un article. On va utiliser un mécanisme d'héritage. On va étendre la classe Article pour créer la classe Promotion.
La nouvelle classe Promotion va récupérer toutes les caractéristiques et toutes les fonctionnalités de la classe Article. C'est ce que l'on appelle l'héritage.
Avec cette présentation de la POO, j'espère vous avoir donné envie de l'apprendre. C'est un investissement. Mais c'est là que vous allez accéder au monde du codage professionnel.




